
In most of our on-premise data centers, compute is traditionally realized by running a few large virtualization clusters (e.g. VMware, Nutanix), backed by one or more shared (file+block) storage solutions and a solid network. Just add power, climate control and security, and your data center is basically ready to go.
However, compute is on the move. Where virtual servers were the only/major type of workload, nowadays we also need to support hosting for Docker containers, serverless/functions, event driven solutions, webAssembly, etc… Meanwhile we learned that running containerized applications is better on smaller clusters than on one single cluster: the Pets versus Cattle paradigm.
Pets versus Cattle
For those who are not familiar with this concept, here is a short explanation. Once we ran servers for multiple years. We updated them periodically and applied changes when new applications/functionally was added to the server. We gave them cute names, noticed some ECC memory warning in the syslog of a server and remembered that we already saw the same error on this server about two months ago. After 5+ years the server got replaced and with tears in our eyes we removed the obsolete server from the rack and moved it to the museum rack. We handled those servers like pets, with all our love and care.
A few years ago we started containerizing, and started orchestrating these workloads in clusters like Docker Swarm or Kubernetes. Containers were recreated faster and faster, from months to days to minutes. Although containers still have host names and IP addresses, we don’t care about it. Containers are handled like cattle. Hosting became more application-centric, sysadmins moved from managing servers to managing clusters and related tools. The clusters became the new pets.
Clusters as cattle
While the number of containers increased rapidly, clusters grew exponentially and became more difficult to maintain. Thanks to DevOps we learned that it is easier to have multiple, smaller clusters: each team or application (group) gets its own cluster, so cluster maintenance could be delegated to the owning teams and aligned with the application release cycles. Also, when a cluster fails, only a limited set of functionality is lost, while other clusters/apps remain available. Cluster deployments become automated and available on-demand via API-call, web form and/or Infrastructure-as-Code. Our clusters now become cattle.
Compute as cattle
Not only container workloads are disposable, so become virtual servers. Containerization is still not a solution for all kinds of applications. For example, large database clusters and ERP systems still prefer to scale vertically and are not suitable to containerize. However it would be great to manage these servers like containers, to limit our tool set and create a universal way of managing workloads. This means that compute in our data center needs to change: virtual machines (and basically any type of workload) should be available on-demand, as cattle!
“Whatever your compute demand is, it should be available as cattle”
Kubernetes as the new compute layer
Nowadays Kubernetes is so much more than just a container hosting platform and orchestrator. Lots of effort has been put into hosting additional compute types, for example:
- The KubeVirt project allows us to create and manage virtual machines as they where containers. KubeVirt requires KVM enabled nodes, since it uses this hypervisor.
- SpinKube provides hosting WebAssembly containers, enabling workloads to start within milliseconds.
- KEDA enables event driven solutions to Kubernetes (comparable to AWS Lambda, Azure Functions, etc). Whenever a call comes in, the required workload is started to handle it. Combined with WebAssembly function apps this can be very powerful.
Using Kubernetes as the new compute layer for your data center is quite different from the more traditional way (large virtualization clusters). It requires both a different skill set and mind set to build and manage. Infrastructure-as-Code should be in your genes to automate everything. You also need a portal to expose the available compute options and allow teams to deploy and maintain their own clusters.
Example solutions
Here are some example setups to create your new compute-as-cattle. These are commercially supported solutions, you can still build your own compute using the related open source solutions, although I don’t think this is suitable for most enterprise organizations.
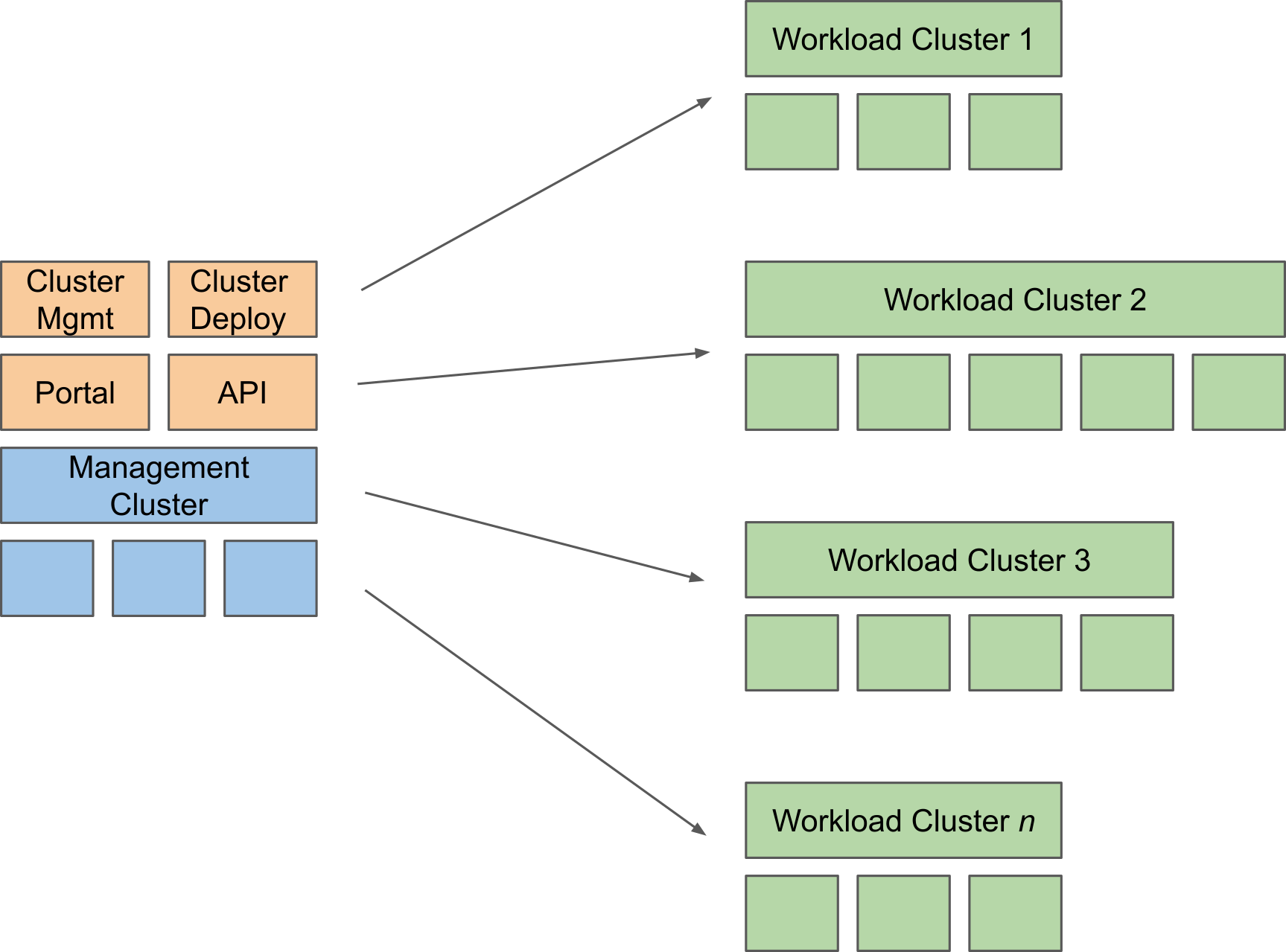
All examples follow a basic pattern: there is a Management Cluster that runs software to deploy Workload Clusters. The Management Cluster also runs the Portal and API. One of the workload clusters will probably be a Services Cluster, running shared services you offer to the application teams; think of your Git repositories, container registry, helm repository, CI tools, etc…
SUSE
SUSE provides a solution based on Harvester and Rancher. Harvester enables bare metal provisioning of your physical servers and can initialize Kubernetes clusters (RKE2). Once the basic cluster is up, Rancher Prime imports the cluster and will manage it. It will also enable server virtualization (based on KubeVirt). Rancher provides a nice web interface to manage your clusters. It centralizes authentication/authorization and provides a web store for your own helm charts. Rancher also allows you to deploy clusters on popular clouds for a hybrid approach.
Red Hat
The Red Hat solution uses Advanced Cluster Management for Kubernetes (ACM), combined with OpenShift (Red Hat’s Kubernetes based hosting platform). ACM allows you to provision OpenShift clusters on bare metal. OpenShift is Red Hat’s implementation of Kubernetes and includes OpenShift Virtualization to deploy and manage virtual machines. ACM can also deploy clusters on popular clouds.
Summary
Kubernetes is a proven foundation for all popular types of compute and can be provisioned as cattle to populate your on-premise data center, optionally combined with cloud for a hybrid solution. Clusters are available on-demand thanks to a portal, API and Infrastructure-as-Code. The platform is maintained by a platform team, that applies Infrastructure-as-Code and CI-pipelines to deliver the platform. The team can work in sprints, delivering a new potential version of the platform in every sprint. There is no more single/large production cluster, instead workloads are spread over numerous clusters. Cluster maintenance ahs less impact and is repeatable, more predictable and eventually automated. Outages will be smaller and will have less impact.
“Running Cattle rather than Pets is a computing infrastructure best practice no matter what layer of the stack” (source)
Qstars IT can help you migrating both your applications and infrastructure to a cloud native landscape, whenever it is on-premise, in the cloud or in a hybrid environment.